A Guide to Data Wrangling in Python

Data is everywhere, and it’s big business. It is estimated that each person generated 1.7 megabytes of data per second in 2020. Globally, internet users generate some 2.5 quintillion bytes of data each day. Companies and governments can now gather real-time user data from all kinds of devices at almost unimaginable volumes. But this creates a new problem: how do we extract value from all this raw data?
The crucial thing to remember here is that data is not information. Gathering data is easy, but it has to be processed and analyzed effectively before it’s useful. In fact, Gartner research estimates that poor quality data costs organizations an average $12.9m every year. It is the job of data scientists - the “sexiest job of the 21st century” - to transform raw data into knowledge, which is then used to inform better decision-making. And one of the most important stages of this process is data wrangling.
What is data wrangling?
Data scientists run complex models to analyze and interpret data so that it generates actionable insights for an organization’s stakeholders. But before they can do this, the data needs to be complete, consistent, structured, and free from bugs.
Data wrangling is essentially the process of ‘cleaning’ unstructured data sets so that they can be explored and analyzed more effectively. What does this mean in practice? It can involve selecting the relevant data from a large set, merging data sets, fixing/removing any corrupt data, identifying anomalies or outliers, standardizing data formats, checking for inconsistencies, etc. Ultimately, the goal is to give analysts data in a user-friendly format, while addressing anything that could undermine the data modeling that is to come.
Data wrangling with Python
Python is generally considered to be a data scientist’s best friend. According to a 2019 survey, 87% of data scientists said they regularly used Python, far more than the next most used languages, SQL (44%) and R (31%).
-png.png)
Python is popular because of its simplicity and flexibility, but also because of the huge number of libraries and frameworks that data scientists can use. Here are five of the most useful and popular for data wrangling:
- Pandas: One of the ‘must have’ tools for data wrangling, Pandas uses data structures called DataFrames, with built-in methods for grouping, filtering, and combining data.
- NumPy: This is primarily used for scientific computing and performing basic and advanced array operations.
- SciPy: This can execute advanced numerical routines, including numerical integration, interpolation, optimization, linear algebra, and statistics.
- Matplotlib: A powerful data visualization library that can convert data into graphs and charts that are more user-friendly when it comes to modeling and analysis.
- Scikit-Learn: A popular machine learning and data modeling tool that is really useful for building regression, clustering, and classification models.
Key steps of data wrangling
1. Collect data
The first step is to import the data you want to analyze. Some key questions to ask at this point are: What data is required? Where is it available? Is it structured or unstructured? How should it be stored and classified so that it is both useful and secure?
- Import raw data: Data sets are commonly saved as CSV, JSON, SQL or Excel files. Once you’ve imported the data file(s), Pandas DataFrames allow you to visualize the data in tabular format (for very large data sets, you can just view the first and last few rows).
- Select/structure data: You can now select the data rows and columns that are relevant to your project. You may also have to merge data from different files to create one data set that you can start working on. At this point, you see why it’s so important to understand what data is required and for what reasons.
2. Cleaning data
This is one of the most important steps, as it is when you fix things that may cause you problems down the line.
- Identify missing data: Any large data set is likely to have some missing entries. With Pandas, when you import a data file, missing fields will be marked with a ‘?’. The first task is to convert every ‘?’ in the data frame to ‘NaN’ (not a number), which is an object that can be worked with.
-png-1.png)
- Deal with missing data: Once all the missing values have been identified, they can either be dropped/removed or replaced with another value. This could be the mean value for the relevant field, or if that’s not possible (e.g. when only integers are valid) then with the most frequent value in that field.
- Correct data formats: Another part of this initial ‘cleaning’ process is ensuring all data formats are correct (e.g. object, text, floating number, integer, etc.). If you are working with dates in Pandas, they also need to be stored in the correct format to be able to use special date-time functions.
-png.png)
3. Transform data
This stage is about converting the data set into a format that can be analyzed/modeled effectively, and there are several techniques.
- Data standardization: This is crucial to ensure there can be a meaningful comparison of data points. For example, if a raw data set includes temperature values measured in both Fahrenheit and Celsius, they must all be converted to one or the other before a model can be run effectively.
- Data normalization: This involves mapping all the nominal data values onto a uniform scale (e.g. from 0 to 1). Making the ranges consistent across variables should help with statistical analysis and ensure fairer comparisons later on.
-png.png)
- Data binning: This is about grouping data values into ‘bins’, which enables analysis of a smaller number of ‘category’ variables and may be more useful. For example, people’s ages are often grouped into ranges (or ‘bins’) such as 18-24, 25-34, 35-44, etc.
4. Explore data
Once the data set is clean, the data exploration can begin. This is like a bridge between the data wrangling and the data modeling phases. It’s a time to get a better understanding of the data set, learn about the main characteristics of the data, and discover some of the patterns or correlations between key data variables.
- Descriptive statistics: Python makes it easy to use methods to view important statistical values (mean, median, max values, standard deviations, etc) in a clear and simple format. This provides a platform for starting statistical analysis.
-png.png)
Sample descriptive statistics for a data set of car variables.
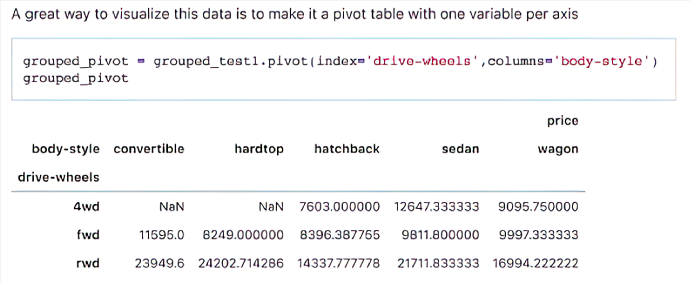
- Grouping: It’s also useful to conduct analysis on ‘groups’ or subsets of the data. Say you are interested in predicting the prices of cars - the basic descriptive statistics will give you the mean price of all the cars in the data set, but grouping allows you to view the mean prices of cars with different characteristics (e.g. two-wheel drive vs four-wheel drive, sedan vs hatchback). Pivot tables are a good way to visualize these groupings with two variables (see image below).
- Correlation: The Pearson correlation is a classical mathematical technique for working out the interdependence between data variables. Figures range from 1 (total positive linear correlation) to -1 (total negative correlation), with 0 signifying zero correlation.
Given the potentially huge volumes of data to be explored, it becomes clear as you begin data exploration why you need to establish specific requirements at the start and structure/clear your data.
Conclusion
If your organization is not extracting value from all the data it can gather and store, then it’s at risk of falling behind. Data is not useful until it can be analyzed and presented as an insight that drives better decision-making. And data cannot be effectively analyzed until it is well structured, clean, and converted into a suitable format. Simply put, that is why good data wrangling is important.
To find out how the talented and experienced data scientists we work with at Jobsity can help your organization improve its data quality, please get in touch.
--
If you want to stay up to date with all the new content we publish on our blog, share your email and hit the subscribe button.
Also, feel free to browse through the other sections of the blog where you can find many other amazing articles on: Programming, IT, Outsourcing, and even Management.


Santiago Mino, VP of Strategy at Jobsity, has been working in Business Development for several years now helping companies and institutions achieve their goals. He holds a degree in Industrial Design, with an extensive and diverse background. Now he spearheads the sales department for Jobsity in the Greater Denver Area.